Why DBOS?
If you're building AI agents, also check out the AI Quickstart.
What is DBOS?
DBOS provides high-performance, easy-to-use durable workflows built on top of Postgres. Essentially, it helps you write long-lived, reliable code that can survive failures, crashes, and restarts without losing state or duplicating work.
In practice, DBOS makes it easier to build reliable systems for use cases like AI agents, data pipelines, payments, or anything that takes minutes, days, or weeks to complete. Rather than bolting on ad-hoc retry logic and database checkpoints, DBOS workflows give you one consistent model for ensuring your programs can recover from any failure from exactly where they left off.
To get started, follow the quickstart to install the open-source library and connect it to a Postgres database. Then, annotate workflows and steps in your program to make it durable! That's all you need to do—DBOS is entirely contained in the open-source library, there's no additional infrastructure for you to configure or manage.
How Does DBOS Work?
DBOS workflows make your program durable by checkpointing its state in Postgres. If your program ever fails, when it restarts all your workflows will automatically resume from the last completed step.
For example, let's say you're running an e-commerce platform where an order goes through multiple steps:
This program looks simple, but making it reliable is deceptively difficult. For example, the program may crash (or its server may be restarted) after validating payment but before shipping an order. Alternatively, the shipping service may experience an outage, leaving the shipping step impossible to complete. In either case, the customer has been charged, but their order is never shipped.
DBOS makes these failures easier to recover from.
All you have to do is annotate your program with decorators like @DBOS.workflow() and @DBOS.step():
@DBOS.step()
def validate_payment():
...
@DBOS.workflow()
def checkout_workflow()
validate_payment()
check_inventory()
ship_order()
notify_customer()
These decorators durably execute your program, persisting its state to a Postgres database:
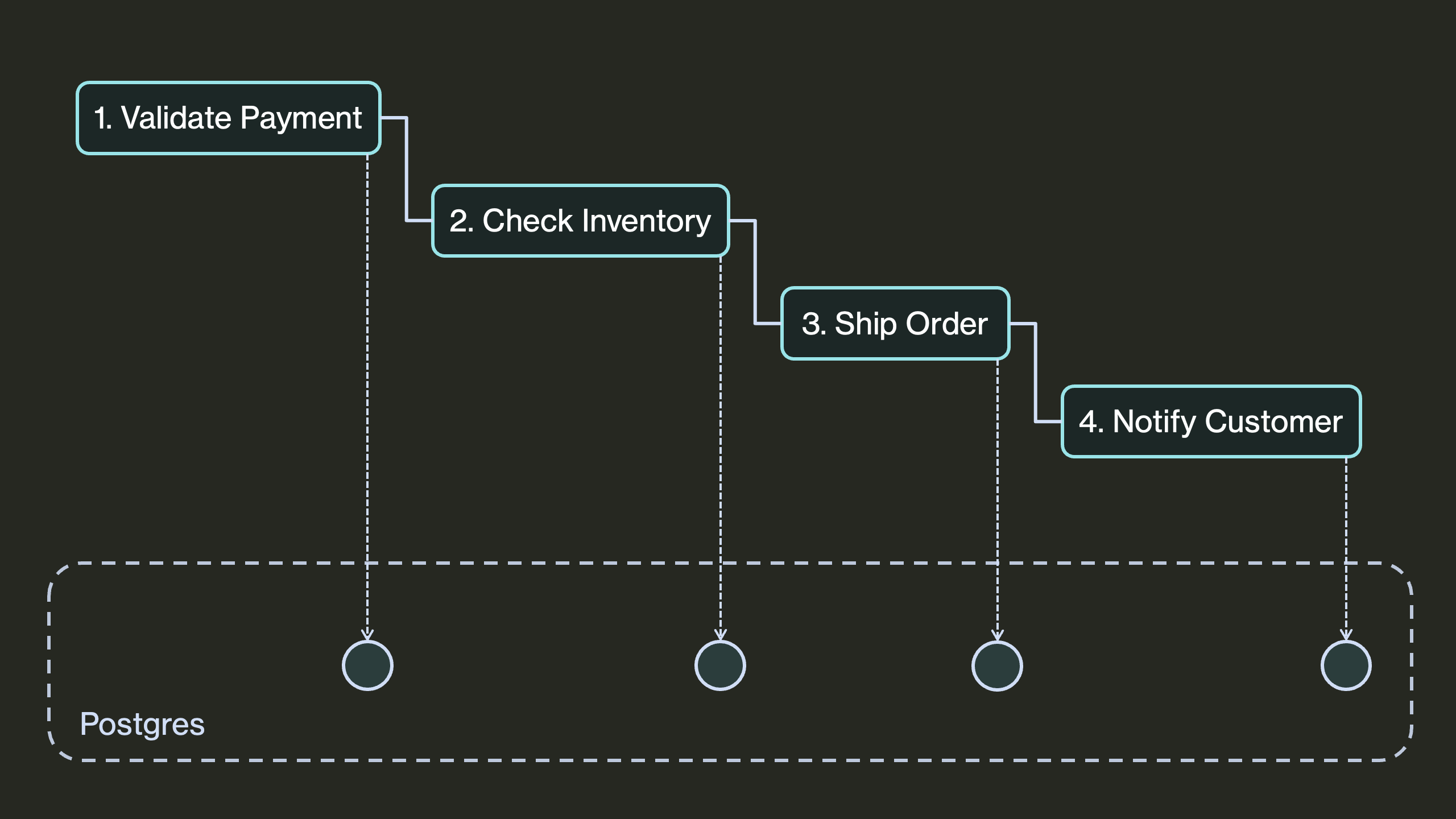
You can think of this stored state as a checkpoint for your program. If your program is ever interrupted or crashes, DBOS uses this saved state to recover it from the last completed step. For example, if your checkout workflow crashes right after validating payment, instead of the order being lost forever, DBOS recovers from a checkpoint and goes on to ship the order. Thus, DBOS makes your application resilient to any failure.
Use Cases
DBOS helps you write complex distributed programs in remarkably few lines of code. For example:
- AI Agents
- Data Pipelines
- Background Tasks
- Business Workflows
Use durable workflows to build fault-tolerant and observable AI agents:
- If a failure occurs after many iterations of a multi-turn agent, workflows help you recover from the last completed step instead of restarting from the beginning.
- Pinpoint the root cause of failures from the workflow dashboard.
- Simplify evals by using fork to restart an agent from a specific step or tool call.
- Seamlessly add human-in-the-loop to your agent.
- Natively integrate with popular frameworks like Pydantic AI, LlamaIndex, OpenAI Agents SDK and Google ADK.
@DBOS.workflow()
def agentic_research_workflow(topic, max_iterations):
research_results = []
for i in range(max_iterations):
research_result = research_query(topic)
research_results.append(research_result)
if not should_continue(research_results):
break
topic = generate_next_topic(topic, research_results)
return synthesize_research_report(research_results)
@DBOS.step()
def research_query(topic):
...
Use durable workflows and queues to build fault-tolerant and observable data pipelines:
- Queues simplify orchestrating tens of thousands of concurrent tasks.
- If a failure occurs during a multi-hour pipeline, workflows help you recover from the last completed step instead of restarting from the beginning.
- Queue flow control helps you manage the resource consumption of your pipelines by controlling how many tasks can run concurrently or how often tasks can start.
DBOS.register_queue("indexing_queue")
@DBOS.workflow()
def indexing_workflow(urls):
handles = []
for url in urls:
handles.append(DBOS.enqueue_workflow("indexing_queue", index_step, url))
return [h.get_result() for h in handles]
Launch durable background tasks using workflows and queues.
- Workflows guarantee background tasks eventually complete, despite restarts and failures.
- Durable sleep and notifications let your tasks wait for days or weeks, or for a notification, before continuing.
- Durably run background tasks directly on your API servers, or use the DBOS client to enqueue tasks from anywhere for execution on dedicated workers or serverless functions.
@DBOS.workflow()
def schedule_task(task, time_to_wait):
DBOS.sleep(time_to_wait)
run_task(task)
Add workflows to your business logic to make it resilient to any failure.
- Write business logic in normal code, with branches, loop, subtasks, and retries.
- Workflows guarantee your critical business processes eventually complete, despite crashes, restarts, and failures.
@DBOS.step()
def validate_payment():
...
@DBOS.workflow()
def checkout_workflow()
validate_payment()
check_inventory()
ship_order()
notify_customer()
DBOS vs. Other Systems
DBOS vs. Temporal
DBOS and Temporal both provide durable workflows. The main difference is that Temporal implements durable workflows in a heavyweight orchestration service, whereas DBOS implements them in a Postgres-backed library.
You can add DBOS to your program by installing the open-source library, connecting it to Postgres, and annotating workflows and steps. By contrast, to add Temporal to your program, you must rearchitect your program to move your workflows and steps (activities) to a cluster of Temporal workers, then manage and scale both the Temporal orchestration server and the datastores it depends on (most commonly Cassandra for durability and Elasticsearch for observability). The Temporal server and its data stores are on the critical path for workflow execution and are single points of failure for your system; if they have downtime your application becomes unavailable. This page makes the comparison in more detail.
DBOS vs. Airflow
DBOS and Airflow both provide workflow abstractions. Airflow is targeted at data science use cases, providing many out-of-the-box connectors but requiring workflows be written as explicit DAGs and externally orchestrating them from an Airflow cluster. Airflow is designed for batch operations and does not provide good performance for streaming or real-time use cases. DBOS is general-purpose, but is often used for data pipelines, allowing developers to write workflows as code and requiring no infrastructure except Postgres.
DBOS vs. Celery/BullMQ
DBOS provides a similar queue abstraction to dedicated queueing systems like Celery or BullMQ: you can declare queues, submit tasks to them, and control their flow with concurrency limits, rate limits, timeouts, prioritization, etc. However, DBOS queues are durable and Postgres-backed and integrate with durable workflows. For example, in DBOS you can write a durable workflow that enqueues a thousand tasks and waits for their results. DBOS checkpoints the workflow and each of its tasks in Postgres, guaranteeing that even if failures or interruptions occur, the tasks will complete and the workflow will collect their results. By contrast, Celery/BullMQ are Redis-backed and don't provide workflows.