How Workflows Work
DBOS durably executes workflows so you can write programs that are resilient to any failure. If a workflow is interrupted for any reason (e.g., a process restarts or crashes), it automatically resumes execution from the last completed step. Here, we'll explain how durable workflows work.
Checkpointing Your Workflows in Postgres.
At a high level, DBOS durably executes your workflows by checkpointing them and their steps in a Postgres database. Before a workflow starts, DBOS records its input in Postgres. Each time a workflow executes a step, DBOS records its output (or the exception it threw, if any) in Postgres. When a workflow finishes, DBOS records its output in Postgres.
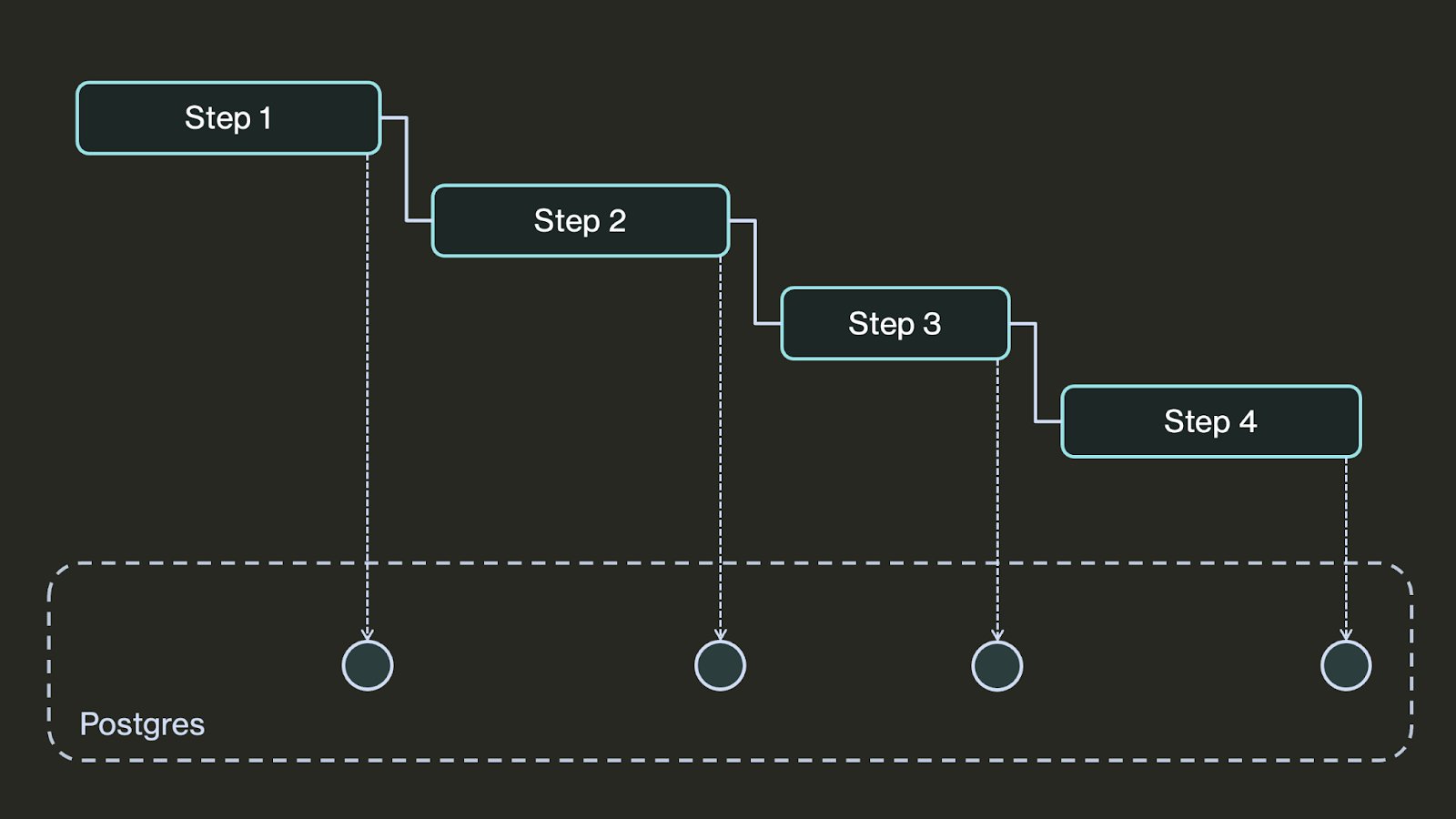
If a process executing a durable workflow is interrupted, upon restart DBOS uses the information saved in the database to resume the workflow from where it left off. First, it restarts the workflow from the beginning, using its saved inputs. While re-executing an pending workflow, it checks before every step if the step has an output stored in the database, meaning it previously completed. If it finds a saved output, it skips re-executing that step and instead uses the saved output. When the workflow gets to the first step that does not have a saved output and hence didn't previously complete, it executes the step normally, thus resuming from the last completed step.
Reliability by Example
To make this clearer, let's look at a simplified checkout workflow for a ticketing site. It first reserves a ticket in the database, then calls out to a third-party platform to process a payment. If the payment doesn't go through, it releases the ticket.
- Python
- TypeScript
@DBOS.workflow()
def checkout_workflow(ticket_info, payment_info):
# Step 1: Reserve the ticket
reserved = reserve_ticket(ticket_info)
if not reserved:
# If the ticket can't be reserved, return failure
return False
# Step 2: Process payment
payment_successful = process_payment(payment_info)
if payment_successful:
# If the payment succeeded, return success
return True
else:
# Step 3: If payment failed, undo the reservation and return failure
undo_reserve_ticket(ticket_info)
return False
@DBOS.workflow()
static async checkoutWorkflow(ticketInfo: TicketInfo, paymentInfo: PaymentInfo) {
// Invoke a transaction to reserve the ticket
const reserved = await Ticket.reserveTicket(ticketInfo)
if (!reserved) {
// If the ticket can't be reserved, return failure
return false
}
// Invoke a step to pay for the ticket
const paymentSuccessful = Ticket.processPayment(paymentInfo)
if (paymentSuccessful) {
// If the payment succeeded, return success
return true
} else {
// If the payment didn't go through, invoke a transaction to undo the reservation and return failure
await Ticket.undoReserveTicket(ticketInfo)
return false
}
}
To make this workflow reliable, DBOS automatically records in Postgres each step it takes.
Before starting, DBOS records its inputs.
As part of the reserve_ticket transaction, DBOS records whether the reservation succeeded or failed.
After the process_payment step completes, DBOS records whether the payment went through.
As part of the undo_reserve_ticket transaction, DBOS records its completion.
Using this information, DBOS can resume the workflow if it is interrupted. Let's say a customer is trying to purchase a ticket and the following events happen:
- Their reservation suceeds.
- Their payment fails.
- The server restarts while undoing the reservation (causing the database to automatically abort that transaction).
It's business-critical that the workflow resumes, as otherwise the customer would have reserved a ticket they never paid for.
When the server restarts, DBOS re-executes the workflow from the beginning.
When it gets to reserve_ticket, it checks the database and finds it previously succeeded, so instead of re-executing the transaction (and potentially reserving a second ticket), it simply returns True.
When it gets to process_payment, it does the same thing, returning False.
Finally, it gets to undo_reserve_ticket, sees no recorded output in the database and executes the function normally, successfuly completing the workflow.
From a user's perspective, the workflow has resumed from where it failed last time!
Requirements for Workflows
Workflows are in most respects normal functions. They can have loops, branches, conditionals, and so on. However, they must meet two requirements:
First, workflows must be deterministic: A workflow implementation must be deterministic: if called multiple times with the same inputs, it should invoke the same steps with the same inputs in the same order. If you need to perform a non-deterministic operation like accessing the database, calling a third-party API, generating a random number, or getting the local time, you shouldn't do it directly in a workflow function. Instead, you should do all database operations in transactions and all other non-deterministic operations in steps. That way, DBOS can capture the output of the non-deterministic operation and avoid re-executing it.
Second, DBOS workflows and steps should not have side effects in memory outside of their own scope. For example, they shouldn't modify global variables. If they do, DBOS cannot guarantee those side effects are persisted during recovery for later steps in the same workflow.