Hacker News Research Agent
This example is also available in TypeScript.
In this example, we use DBOS to build an AI deep research agent that autonomously searches Hacker News for information on any topic.
This example demonstrates how to build reliable, durable AI agents with durable workflows. The agent starts with a research topic, iteratively researches related topics, then synthesizes findings into a comprehensive report. Because the agent is implemented as a durable workflow, it can recover from any failure and continue research from where it left off, ensuring no work is lost.
This example also demonstrates how easy it is to add DBOS to an existing agentic application. Adding DBOS to this agent required changing <20 lines of code. All you have to do is annotate workflows and steps.
All source code is available on GitHub.
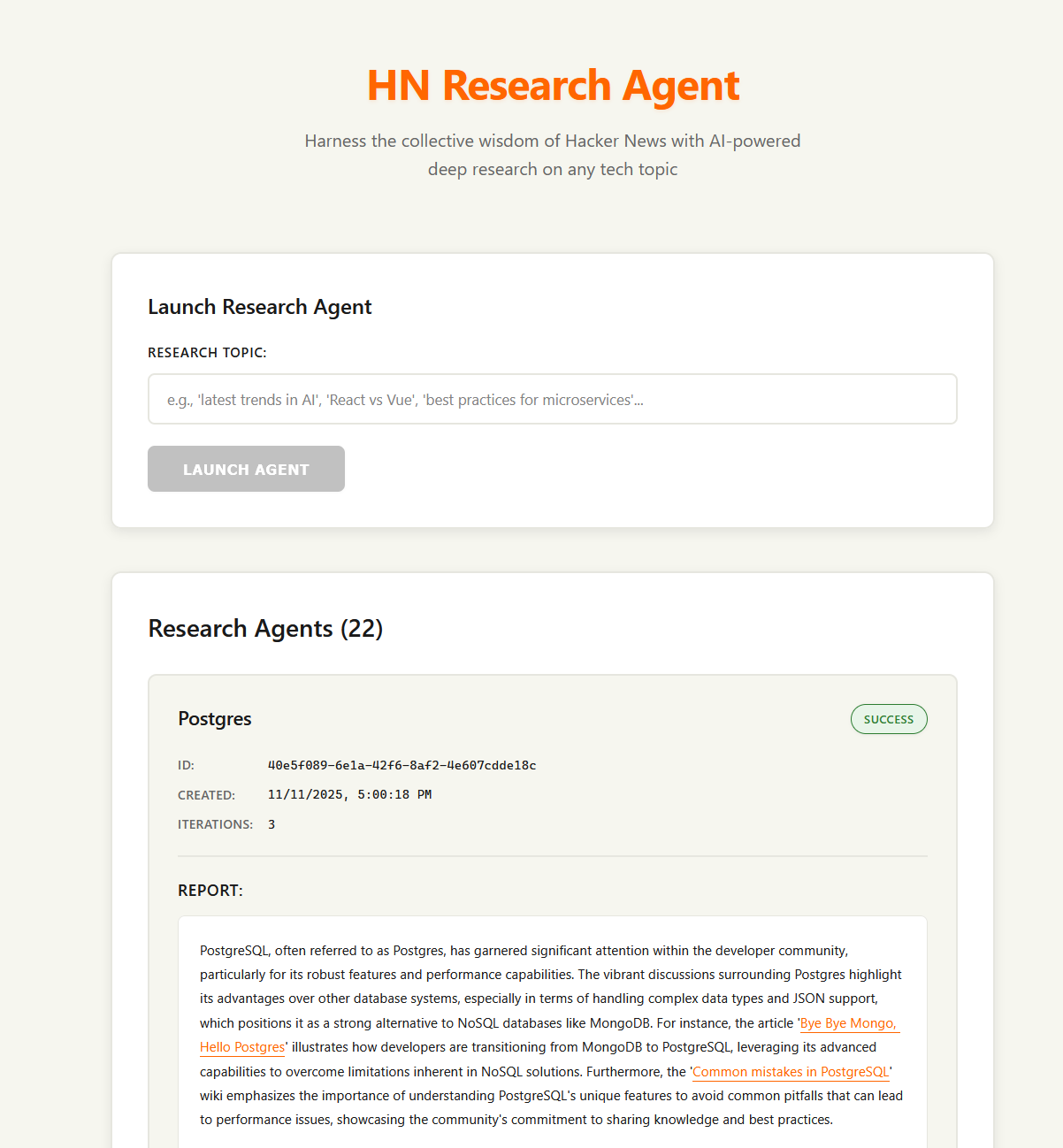
Main Research Workflow
The core of the agent is the main research workflow. It starts with a topic and autonomously explores related queries until it has enough information, then synthesizes a final report.
@DBOS.workflow()
def agentic_research_workflow(topic: str, max_iterations: int = 3):
"""
This agent starts with a research topic then:
1. Searches Hacker News for information on that topic.
2. Iteratively searches related topics, collecting information.
3. Makes decisions about when to continue.
4. Synthesizes findings into a final report.
"""
console.print(f"[dim]🎯 Starting agentic research for: {topic}[/dim]")
# Set and update an agent status the frontend can display
agent_status = AgentStatus(
created_at=datetime.now().isoformat(),
topic=topic,
iterations=0,
report=None,
status="PENDING",
)
DBOS.set_event(AGENT_STATUS, agent_status)
all_findings = []
current_iteration = 0
current_topic = topic
# Main agentic research loop
while current_iteration < max_iterations:
current_iteration += 1
agent_status.iterations = current_iteration
DBOS.set_event(AGENT_STATUS, agent_status)
# Research the next topic in a child workflow
evaluation = research_topic(topic, current_topic)
all_findings.append(evaluation.model_dump())
# Evaluate whether to continue research
should_continue = should_continue_step(
topic, all_findings, current_iteration, max_iterations
)
if not should_continue:
break
# Generate next research question based on findings
if current_iteration < max_iterations:
follow_up_topic = generate_follow_ups_step(
topic, all_findings, current_iteration
)
if follow_up_topic:
current_topic = follow_up_topic
else:
break
# Final step: Synthesize all findings into comprehensive report
final_report = synthesize_findings_step(topic, all_findings)
agent_status.report = final_report.report
DBOS.set_event(AGENT_STATUS, agent_status)
Research Query Workflow
Each iteration of the main research workflow calls a child workflow that searches Hacker News for information about a query, then evaluates and returns its findings.
@DBOS.workflow()
def research_topic(topic: str, query: str) -> EvaluationResult:
"""Research a topic selected by the main agentic workflow."""
# Step 1: Search Hacker News for stories about the topic
stories = search_hackernews_step(query, max_results=30)
# Step 2: Gather comments from all stories found
comments = []
if stories:
for i, story in enumerate(stories):
story_id = story.get("objectID")
title = story.get("title", "Unknown")[:50]
num_comments = story.get("num_comments", 0)
if story_id and num_comments > 0:
story_comments = get_comments_step(story_id, max_comments=10)
comments.extend(story_comments)
# Step 3: Evaluate gathered data and return findings
return evaluate_results_step(topic, query, stories, comments)
Agent Decision-Making Steps
The agent's intelligence comes from three key step functions that handle decision-making:
Agent Evaluation Step
@DBOS.step()
def evaluate_results_step(
topic: str,
query: str,
stories: List[Dict[str, Any]],
comments: Optional[List[Dict[str, Any]]] = None,
) -> EvaluationResult:
"""Agent evaluates search results and extracts insights."""
# Create detailed content digest for LLM
stories_text = ""
top_stories = []
# Evaluate only the top 10 most relevant (per HN search) stories
for i, story in enumerate(stories[:10]):
title = story.get("title", "No title")
url = story.get("url", "No URL")
hn_url = f"https://news.ycombinator.com/item?id={story.get('objectID', '')}"
points = story.get("points", 0)
num_comments = story.get("num_comments", 0)
author = story.get("author", "Unknown")
stories_text += f"Story {i+1}:\n"
stories_text += f" Title: {title}\n"
stories_text += f" Points: {points}, Comments: {num_comments}\n"
stories_text += f" URL: {url}\n"
stories_text += f" HN Discussion: {hn_url}\n"
stories_text += f" Author: {author}\n\n"
# Store top stories for reference
top_stories.append(
StoryReference(
title=title,
url=url,
hn_url=hn_url,
points=points,
num_comments=num_comments,
author=author,
objectID=story.get("objectID", ""),
)
)
comments_text = ""
if comments:
for i, comment in enumerate(comments[:20]): # Limit to top 20 comments
comment_text = comment.get("comment_text", "")
if comment_text:
author = comment.get("author", "Unknown")
# Get longer excerpts for better analysis
excerpt = (
comment_text[:400] + "..."
if len(comment_text) > 400
else comment_text
)
comments_text += f"Comment {i+1}:\n"
comments_text += f" Author: {author}\n"
comments_text += f" Text: {excerpt}\n\n"
prompt = f"""
You are a research agent evaluating search results for: {topic}
Query used: {query}
Stories found:
{stories_text}
Comments analyzed:
{comments_text}
Provide a DETAILED analysis with specific insights, not generalizations. Focus on:
- Specific technical details, metrics, or benchmarks mentioned
- Concrete tools, libraries, frameworks, or techniques discussed
- Interesting problems, solutions, or approaches described
- Performance data, comparison results, or quantitative insights
- Notable opinions, debates, or community perspectives
- Specific use cases, implementation details, or real-world examples
Return JSON with:
- "insights": String array of specific, technical insights with context
- "relevance_score": Number 1-10
- "summary": Brief summary of findings
- "key_points": Array of most important points discovered
"""
messages = [
{
"role": "system",
"content": "You are a research evaluation agent. Analyze search results and provide structured insights in JSON format.",
},
{"role": "user", "content": prompt},
]
response = call_llm(messages, max_tokens=2000)
cleaned_response = clean_json_response(response)
evaluation_dict = json.loads(cleaned_response)
evaluation_dict["query"] = query
evaluation_dict["top_stories"] = top_stories
return EvaluationResult(**evaluation_dict)
Follow-up Query Generation Step
@DBOS.step()
def generate_follow_ups_step(
topic: str, current_findings: List[Dict[str, Any]], iteration: int
) -> Optional[str]:
"""Agent generates follow-up research queries based on current findings."""
findings_summary = ""
for finding in current_findings:
findings_summary += f"Query: {finding.get('query', 'Unknown')}\n"
findings_summary += f"Summary: {finding.get('summary', 'No summary')}\n"
findings_summary += f"Key insights: {finding.get('insights', [])}\n"
findings_summary += (
f"Unanswered questions: {finding.get('unanswered_questions', [])}\n\n"
)
prompt = f"""
You are a research agent investigating: {topic}
This is iteration {iteration} of your research.
Current findings:
{findings_summary}
Generate 2-4 SHORT KEYWORD-BASED search queries for Hacker News that explore DIVERSE aspects of {topic}.
CRITICAL RULES:
1. Use SHORT keywords (2-4 words max) - NOT long sentences
2. Focus on DIFFERENT aspects of {topic}, not just one narrow area
3. Use terms that appear in actual Hacker News story titles
4. Avoid repeating previous focus areas
5. Think about what tech people actually discuss about {topic}
For {topic}, consider diverse areas like:
- Performance/optimization
- Tools/extensions
- Comparisons with other technologies
- Use cases/applications
- Configuration/deployment
- Recent developments
GOOD examples: ["postgres performance", "database tools", "sql optimization"]
BAD examples: ["What are the best practices for PostgreSQL optimization?"]
Return only a JSON array of SHORT keyword queries: ["query1", "query2", "query3"]
"""
messages = [
{
"role": "system",
"content": "You are a research agent. Generate focused follow-up queries based on current findings. Return only JSON array.",
},
{"role": "user", "content": prompt},
]
response = call_llm(messages)
cleaned_response = clean_json_response(response)
queries = json.loads(cleaned_response)
return queries[0] if isinstance(queries, list) and len(queries) > 0 else None
Continuation Decision Step
@DBOS.step()
def should_continue_step(
topic: str,
all_findings: List[Dict[str, Any]],
current_iteration: int,
max_iterations: int,
) -> bool:
"""Agent decides whether to continue research or conclude."""
if current_iteration >= max_iterations:
return {
"should_continue": False,
"reason": f"Reached maximum iterations ({max_iterations})",
}
# Analyze findings completeness
findings_summary = ""
total_relevance = 0
for finding in all_findings:
findings_summary += f"Query: {finding.get('query', 'Unknown')}\n"
findings_summary += f"Summary: {finding.get('summary', 'No summary')}\n"
findings_summary += f"Relevance: {finding.get('relevance_score', 5)}/10\n"
total_relevance += finding.get("relevance_score", 5)
avg_relevance = total_relevance / len(all_findings) if all_findings else 0
prompt = f"""
You are a research agent investigating: {topic}
Current iteration: {current_iteration}/{max_iterations}
Findings so far:
{findings_summary}
Average relevance score: {avg_relevance:.1f}/10
Decide whether to continue research or conclude. PRIORITIZE THOROUGH EXPLORATION - continue if:
1. Current iteration is less than 75% of max_iterations
2. Average relevance is above 6.0 and there are likely unexplored aspects
3. Recent queries found significant new information
4. The research seems to be discovering diverse perspectives on the topic
Only stop early if:
- Average relevance is below 5.0 for multiple iterations
- No new meaningful information in the last 2 iterations
- Research appears to be hitting diminishing returns
Return JSON with:
- "should_continue": boolean
"""
messages = [
{
"role": "system",
"content": "You are a research decision agent. Evaluate research completeness and decide whether to continue. Return JSON.",
},
{"role": "user", "content": prompt},
]
raw_response = call_llm(messages)
cleaned_response = clean_json_response(raw_response)
json_response = json.loads(cleaned_response)
response = ShouldContinueResult(**json_response)
return response.should_continue
Search API Steps
After deciding what terms to search for, the agent calls these steps to retrieve stories and comments from Hacker News.
Hacker News API Steps
@DBOS.step()
def search_hackernews_step(query: str, max_results: int = 20) -> List[Dict[str, Any]]:
"""Search Hacker News stories using Algolia API."""
params = {"query": query, "hitsPerPage": max_results, "tags": "story"}
with httpx.Client(timeout=30.0) as client:
response = client.get("https://hn.algolia.com/api/v1/search", params=params)
response.raise_for_status()
return response.json()["hits"]
@DBOS.step()
def get_comments_step(story_id: str, max_comments: int = 50) -> List[Dict[str, Any]]:
"""Get comments for a specific Hacker News story."""
params = {"tags": f"comment,story_{story_id}", "hitsPerPage": max_comments}
with httpx.Client(timeout=30.0) as client:
response = client.get("https://hn.algolia.com/api/v1/search", params=params)
response.raise_for_status()
return response.json()["hits"]
Synthesize Findings Step
Finally, after concluding its research, the agentic workflow calls this step to synthesize its findings into a report.
Synthesize Findings Step
@DBOS.step()
def synthesize_findings_step(
topic: str, all_findings: List[Dict[str, Any]]
) -> ResearchReport:
"""Synthesize all research findings into a comprehensive report."""
findings_text = ""
story_links = []
for i, finding in enumerate(all_findings, 1):
findings_text += f"\n=== Finding {i} ===\n"
findings_text += f"Query: {finding.get('query', 'Unknown')}\n"
findings_text += f"Summary: {finding.get('summary', 'No summary')}\n"
findings_text += f"Key Points: {finding.get('key_points', [])}\n"
findings_text += f"Insights: {finding.get('insights', [])}\n"
# Extract story links and details for reference
if finding.get("top_stories"):
for story in finding["top_stories"]:
story_links.append(
{
"title": story.get("title", "Unknown"),
"url": story.get("url", ""),
"hn_url": f"https://news.ycombinator.com/item?id={story.get('objectID', '')}",
"points": story.get("points", 0),
"comments": story.get("num_comments", 0),
}
)
# Build comprehensive story and citation data
story_citations = {}
citation_id = 1
for finding in all_findings:
if finding.get("top_stories"):
for story in finding["top_stories"]:
story_id = story.get("objectID", "")
if story_id and story_id not in story_citations:
story_citations[story_id] = {
"id": citation_id,
"title": story.get("title", "Unknown"),
"url": story.get("url", ""),
"hn_url": story.get("hn_url", ""),
"points": story.get("points", 0),
"comments": story.get("num_comments", 0),
}
citation_id += 1
# Create citation references text
citations_text = "\n".join(
[
f"[{cite['id']}] {cite['title']} ({cite['points']} points, {cite['comments']} comments) - {cite['hn_url']}"
+ (f" - {cite['url']}" if cite["url"] else "")
for cite in story_citations.values()
]
)
prompt = f"""
You are a research analyst. Synthesize the following research findings into a comprehensive, detailed report about: {topic}
Research Findings:
{findings_text}
Available Citations:
{citations_text}
IMPORTANT: You must return ONLY a valid JSON object with no additional text, explanations, or formatting.
Create a comprehensive research report that flows naturally as a single narrative. Include:
- Specific technical details and concrete examples
- Actionable insights practitioners can use
- Interesting discoveries and surprising findings
- Specific tools, libraries, or techniques mentioned
- Performance metrics, benchmarks, or quantitative data when available
- Notable opinions or debates in the community
- INLINE LINKS: When making claims, include clickable links directly in the text using this format: [link text](HN_URL)
- Use MANY inline links throughout the report. Aim for at least 4-5 links per paragraph.
CRITICAL CITATION RULES - FOLLOW EXACTLY:
1. NEVER replace words with bare URLs like "(https://news.ycombinator.com/item?id=123)"
2. ALWAYS write complete sentences with all words present
3. Add citations using descriptive link text in brackets: [descriptive text](URL)
4. Every sentence must be grammatically complete and readable without the links
5. Links should ALWAYS be to the Hacker News discussion, NEVER directly to the article.
CORRECT examples:
"PostgreSQL's performance improvements have been significant in recent versions, as discussed in [community forums](https://news.ycombinator.com/item?id=123456), with developers highlighting [specific optimizations](https://news.ycombinator.com/item?id=789012) in query processing."
"Redis performance issues can stem from common configuration mistakes, which are well-documented in [troubleshooting guides](https://news.ycombinator.com/item?id=345678) and [community discussions](https://news.ycombinator.com/item?id=901234)."
"React's licensing changes have sparked significant community debate, as seen in [detailed discussions](https://news.ycombinator.com/item?id=15316175) about the implications for open-source projects."
WRONG examples (NEVER DO THIS):
"Community discussions reveal a strong interest in the (https://news.ycombinator.com/item?id=18717168) and the common pitfalls"
"One significant topic is the (https://news.ycombinator.com/item?id=15316175), which raises important legal considerations"
Always link to relevant discussions for:
- Every specific tool, library, or technology mentioned
- Performance claims and benchmarks
- Community opinions and debates
- Technical implementation details
- Companies or projects referenced
- Version releases or updates
- Problem reports or solutions
Return a JSON object with this exact structure:
{{
"report": "A comprehensive research report written as flowing narrative text with inline clickable links [like this](https://news.ycombinator.com/item?id=123). Include specific technical details, tools, performance metrics, community opinions, and actionable insights. Make it detailed and informative, not just a summary."
}}
"""
messages = [
{
"role": "system",
"content": "You are a research analyst. Provide comprehensive synthesis in JSON format.",
},
{"role": "user", "content": prompt},
]
raw_response = call_llm(messages, max_tokens=3000)
cleaned_response = clean_json_response(raw_response)
json_response = json.loads(cleaned_response)
return ResearchReport(**json_response)
API Endpoints
The agent has two API endpoints used by its frontend: one that starts a new agent researching a topic and one that retrieves agent statuses.
This endpoint starts a durable agent in the background:
@app.post("/agents")
def start_agent(request: AgentStartRequest):
# Start a durable agent in the background
DBOS.start_workflow(agentic_research_workflow, request.topic)
return {"ok": True}
This endpoint returns the statuses of all agents.
It lists all agents with DBOS.list_workflows, then retrieves the status of each using DBOS.get_event.
@app.get("/agents", response_model=list[AgentStatus])
async def list_agents():
# List all active agents and retrieve their statuses
agent_workflows = await DBOS.list_workflows_async(
name=agentic_research_workflow.__qualname__,
sort_desc=True,
)
statuses: list[AgentStatus] = await asyncio.gather(
*[DBOS.get_event_async(w.workflow_id, AGENT_STATUS) for w in agent_workflows]
)
for workflow, status in zip(agent_workflows, statuses):
status.status = workflow.status
status.agent_id = workflow.workflow_id
return statuses
Try it Yourself!
Clone and enter the dbos-demo-apps repository:
git clone https://github.com/dbos-inc/dbos-demo-apps.git
cd python/hacker-news-agent
Then follow the instructions in the README to run the app.