Document Ingestion Pipeline
In this example, we'll use DBOS to build a reliable and scalable data processing pipeline. We'll show how DBOS can help you horizontally scale an application to process many items concurrently and seamlessly recover from failures. Specifically, we'll build a pipeline that indexes PDF documents for RAG, though you can use a similar design pattern to build almost any data pipeline.
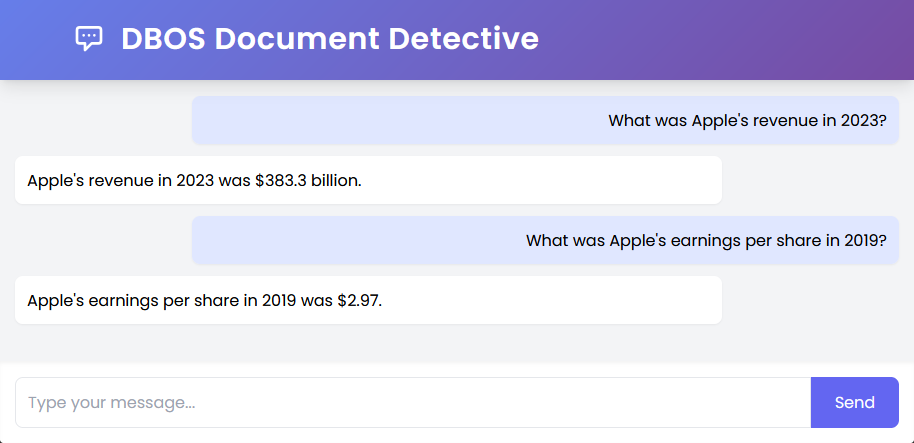
To show the pipeline works, we'll also build a simple chat agent that can accurately answer questions about the indexed documents. For example, after ingesting the last few years of Apple 10-K filings, the chat agent can accurately answer questions about Apple's financials:
All source code is available on GitHub.
Import and Initialize the App
Let's start with imports and initializing DBOS.
import os
from tempfile import TemporaryDirectory
from typing import List
import requests
import uvicorn
from dbos import DBOS, DBOSConfig, WorkflowHandle
from fastapi import FastAPI
from fastapi.responses import HTMLResponse
from llama_index.core import Document, Settings, StorageContext, VectorStoreIndex
from llama_index.readers.file import PDFReader
from llama_index.vector_stores.postgres import PGVectorStore
from pydantic import BaseModel, HttpUrl
from sqlalchemy import make_url
database_url = os.environ.get("DBOS_SYSTEM_DATABASE_URL")
if not database_url:
raise Exception("DBOS_SYSTEM_DATABASE_URL not set")
app = FastAPI()
config: DBOSConfig = {
"name": "document-detective",
"application_version": "0.1.0",
"system_database_url": database_url,
"conductor_key": os.environ.get("CONDUCTOR_KEY"),
}
DBOS(config=config)
Next, let's initialize LlamaIndex to store and query the vector index we'll be constructing.
def configure_index():
Settings.chunk_size = 512
db = make_url(database_url)
vector_store = PGVectorStore.from_params(
database=db.database,
host=db.host,
password=db.password,
port=db.port,
user=db.username,
perform_setup=False, # Set up during migration step
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex([], storage_context=storage_context)
chat_engine = index.as_chat_engine()
return index, chat_engine
index, chat_engine = configure_index()
Building a Durable Data Ingestion Pipeline
Now, let's write the document ingestion pipeline. Because ingesting and indexing documents may take a long time, we need to build a pipeline that's both concurrent and reliable. It needs to process multiple documents at once and it needs to be resilient to failures, so if the application is interrupted or restarted, or encounters an error, it can recover from where it left off instead of restarting from the beginning or losing some documents entirely.
We'll build a concurrent, reliable data ingestion pipeline using DBOS workflows and queues. This workflow takes in a batch of document URLs, enqueues them all for indexing, and waits for all documents to finish being indexed. If it's ever interrupted or restarted, it recovers the indexing of each document from the last completed step, guaranteeing that every document is indexed and none are lost.
@DBOS.workflow()
def index_documents(urls: List[HttpUrl]):
handles: List[WorkflowHandle] = []
# Enqueue each document for indexing
for url in urls:
handle = DBOS.enqueue_workflow("indexing_queue", index_document, url)
handles.append(handle)
# Wait for all documents to finish indexing, count the total number of indexed pages
indexed_pages = 0
for handle in handles:
indexed_pages += handle.get_result()
print(f"Indexed {len(urls)} documents totaling {indexed_pages} pages")
This workflow indexes an individual document.
It calls two steps: download_document to download the document and parse it into pages, then index_page to add a parsed page to the vector index.
@DBOS.workflow()
def index_document(document_url: HttpUrl) -> int:
pages = download_document(document_url)
for page in pages:
index_page(page)
return len(pages)
Here's the code for the steps in index_document:
@DBOS.step()
def download_document(document_url: HttpUrl):
# Download the document to a temporary file
print(f"Downloading document from {document_url}")
with TemporaryDirectory() as temp_dir:
temp_file_path = os.path.join(temp_dir, "document.pdf")
with open(temp_file_path, "wb") as temp_file:
with requests.get(document_url, stream=True) as r:
r.raise_for_status()
for page in r.iter_content(chunk_size=8192):
temp_file.write(page)
# Parse the document into pages
reader = PDFReader()
pages = reader.load_data(temp_file_path)
return pages
@DBOS.step()
def index_page(page: Document):
# Insert a page into the vector index
try:
index.insert(page)
except Exception as e:
print("Error indexing page:", page, e)
Next, let's write the endpoint for indexing. It starts the indexing workflow in the background on a batch of documents.
class URLList(BaseModel):
urls: List[HttpUrl]
@app.post("/index")
def index_endpoint(urls: URLList):
DBOS.start_workflow(index_documents, urls.urls)
Chatting With Your Data
Now, let's write a simple in-memory chat agent so we can query our data. Every time it gets a question, it answers using a RAG chat engine powered by the vector index.
class ChatSchema(BaseModel):
message: str
chat_history = []
@app.post("/chat")
def chat(chat: ChatSchema):
query = {"content": chat.message, "isUser": False}
chat_history.append(query)
responseMessage = str(chat_engine.chat(chat.message))
response = {"content": responseMessage, "isUser": True}
chat_history.append(response)
return response
@app.get("/history")
def history_endpoint():
return chat_history
We'll serve the app's frontend from an HTML file using FastAPI.
@app.get("/")
def frontend():
with open(os.path.join("html", "app.html")) as file:
html = file.read()
return HTMLResponse(html)
Finally, let's write a main function to launch DBOS and start our app:
if __name__ == "__main__":
DBOS.launch()
DBOS.register_queue("indexing_queue")
uvicorn.run(app, host="0.0.0.0", port=8000)
Try it Yourself!
Clone and enter the dbos-demo-apps repository:
git clone https://github.com/dbos-inc/dbos-demo-apps.git
cd python/document-detective
Then follow the instructions in the README to run the app.