DBOS Architecture
DBOS provides a high-performance, easy-to-use library for durable workflows built on top of Postgres.
You use DBOS by installing the open-source library into your application and annotating workflows and steps. While your application runs, DBOS checkpoints those workflows and steps to a Postgres database. When failures occur, whether from crashes, interruptions, or restarts, DBOS uses those checkpoints to recover each of your workflows from the last completed step.
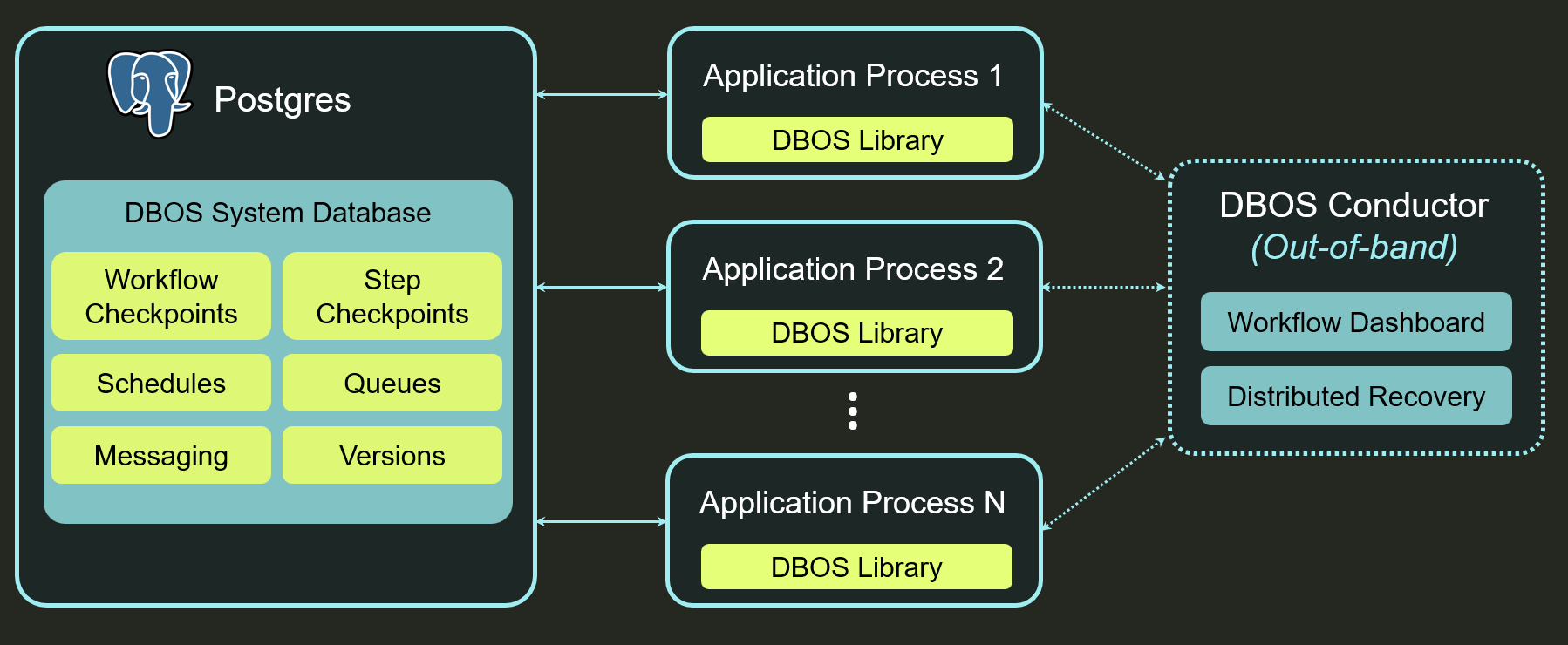
Architecturally, an application built with DBOS looks the below diagram. The open-source DBOS library uses Postgres to orchestrate durable workflows and queues. There's no separate orchestration server and no infrastructure required besides Postgres. When running in production, we also recommend connecting your DBOS applications to Conductor, a "control plane" for your durable workflows that coordinates workflow recovery to guarantee high availability and provides operational tooling such as an admin UI and dashboard, observability integrations, and managed workflow retention policies.
To learn more about how to add DBOS to your application, check out the language-specific integration guides (Python, TypeScript, Go, Java).
Using DBOS in a Distributed Setting
You can create a distributed DBOS application by launching multiple server processes (sometimes called "workers" or "executors") on a variety of platforms, such as a Kubernetes cluster, a fleet of EC2 instances, or a serverless platform like Google Cloud Run. Within an application, each server must connect to the same Postgres database, called the system database. This database stores all workflow checkpoints, step outputs, and schedule and queue state. To distribute work across many servers in a cluster, you should use durable queues. Distributed applications should also connect to DBOS Conductor, the control plane for cluster-wide observability and management. For example, if one of your workers crashes or fails, Conductor detects the failure and automatically recovers its workflows to a compatible live worker.
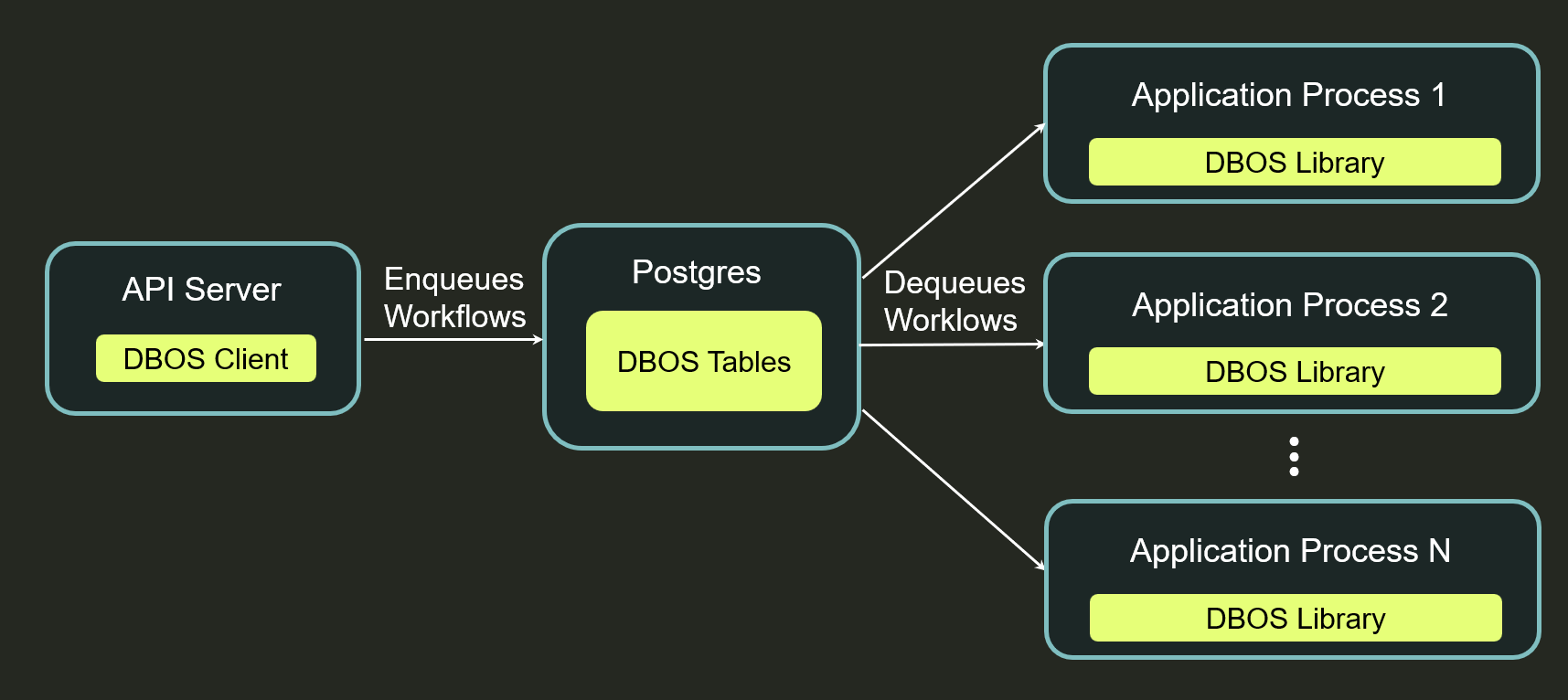
When using DBOS in a distributed setting, you often want to implement durable workflows in one service, but manage them from another service. For example, you may want your API server to enqueue and monitor durable jobs on your data processing service. You can use the DBOS Client (Python, TypeScript, Go, Java) to programmatically interact with your application from external code. Your API server can create a client connected to your data processing service's system database and use it to enqueue a job, monitor the job's status, and retrieve its result when complete. Here's a diagram of what that might look like:
You may also have multiple applications or services that need durable workflows. For example, you might have a service that runs business workflows, a service that handles data ingestion, and a service that runs an AI agent. You can separately add DBOS to each of these applications. Each application should have a separate system database and a unique Conductor application name. This doesn't require multiple Postgres servers: a single physical Postgres server can host multiple logical system databases, with each database serving a separate DBOS application.
Within an application, all servers must use the same programming language. However, cross-language interaction is possible via the DBOS Client. For example a Typescript application can enqueue workflows onto a separate Python application, monitor their progress and gather results. Cross-language operations are documented here.
How DBOS Scales
You can easily scale a DBOS application by adding more servers to it, so the scalability of DBOS is fundamentally determined by the database it is connected to. The only overhead DBOS adds is database writes: one database write per step (to checkpoint the step's outcome) plus two additional database writes per workflow (one at the beginning to checkpoint workflow inputs, one at the end to checkpoint the workflow outcome).
In benchmarks, a DBOS application using a single Postgres database can sustain a throughput of >40K workflows or steps per second. Scaling beyond that is possible by sharding workflows across multiple Postgres databases.
It is worth noting that the since DBOS checkpoints workflow inputs and outputs and step outputs, the sizes of its writes are determined by the sizes of your inputs and outputs. If your steps return small objects, the write sizes are negligible, but if they return large files, the write sizes are large. Thus, we recommend architecting steps to avoid large output sizes (for example, store large files in cloud blob storage like S3 and have steps return pointers to those files).
How Workflow Recovery Works
DBOS achieves fault tolerance by checkpointing workflows and steps. Every workflow input and step output is durably stored in the system database. When workflow execution fails, whether from crashes, network issues, or server restarts, DBOS leverages these checkpoints to recover workflows from their last completed step.
Workflow recovery occurs in three steps:
-
First, DBOS detects interrupted workflows. In single-node deployments, this happens automatically at startup when DBOS scans for incomplete (PENDING) workflows. In a distributed deployment, some coordination is required, either automatically through services like DBOS Conductor or manually.
-
Next, DBOS restarts each interrupted workflow by calling it with its checkpointed inputs. As the workflow re-executes, it checks before each step if that step's output is checkpointed in Postgres. If there is a checkpoint, the step returns the checkpointed output instead of executing.
-
Eventually, the recovered workflow reaches a step with no checkpoint. This marks the point where the original execution failed. The recovered workflow executes that step normally and proceeds from there, thus resuming from the last completed step.
For DBOS to be able to safely recover a workflow, your code must satisfy two requirements:
-
The workflow function must be deterministic: if executed multiple times, with the same arguments and step return values, the workflow should invoke the same steps with the same inputs in the same order. If you need to perform any non-deterministic operation like accessing the database, calling a third-party API, generating a random number, or getting the local time, you should do it in a step instead of directly in the workflow function.
-
Steps should be idempotent, meaning it should be safe to retry them multiple times. If a workflow fails while executing a step, it retries the step during recovery. However, once a step completes and is checkpointed, it is never re-executed.
Upgrading Workflow Code
One challenge you may encounter when operating long-running durable workflows in production is how to deploy breaking changes without disrupting in-progress workflows. A breaking change to a workflow is any change in what steps run or the order in which steps run. The issue is that if a breaking change was made to a workflow, the checkpoints created by a workflow that started on the previous version of the code may not match the steps called by the workflow in the new version of the code, which makes the workflow difficult to recover.
DBOS supports two strategies for safely upgrading workflow code: patching and versioning. When using patching, you add DBOS patch statements to your code to make a breaking change in a conditional so old workflows can safely recover. When using versioning, DBOS versions applications and workflows so workflows only recover to processes running compatible code. Learn more about both strategies in the workflow upgrade tutorial (Python, TypeScript, Go, Java).
Durable Queues
One powerful feature of DBOS is that you can enqueue workflows for distributed execution with flow control. You can enqueue a workflow from within your DBOS application using the DBOS library or from another application using a DBOS Client (Python, TypeScript, Go, Java).
An enqueued workflow may be dequeued and executed by your application's servers. All processes running DBOS periodically poll queues to find and execute new work. You can configure which processes listen to which queues.
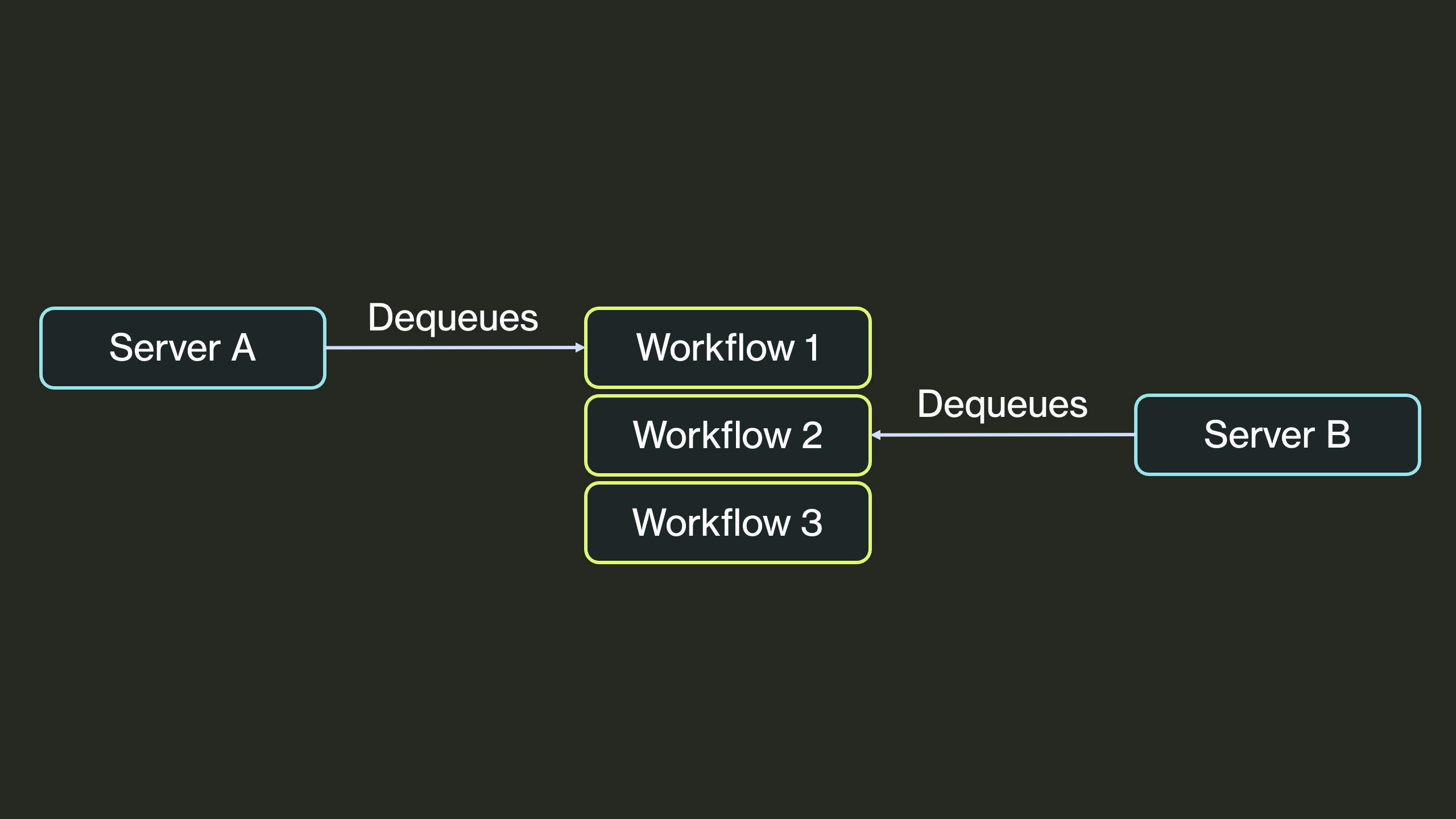
To help you operate at scale, DBOS queues provide flow control. You can customize the rate and concurrency at which workflows are dequeued and executed. For example, you can set a worker concurrency for each of your queues on each of your servers, limiting how many workflows from that queue may execute concurrently on that server. For more information on queues, see the docs (Python, TypeScript, Go, Java).
Operating DBOS in Production with Conductor
When operating DBOS durable workflows in production, we strongly recommend connecting your application to Conductor. Conductor is the control plane for your durable workflows, providing:
- High availability: In a distributed environment with many executors running durable workflows, Conductor automatically detects when the execution of a durable workflow is interrupted (for example, if its executor is restarted, interrupted, or crashes) and recovers the workflow to another healthy executor.
- Workflow and queue observability: Conductor provides dashboards of all active and past workflows and all queued tasks as well as real-time workflow visualization.
- Workflow and queue management: From the Conductor dashboard, you can pause any workflow execution, start any stopped or enqueued workflow, or restart any workflow from a specific step. This is useful for rapidly responding to incidents or debugging.
- Managed Retention Policies: From the Conductor dashboard, manage how much workflow history each of your applications should retain and for how long to retain it.
- Observability Integrations: Conductor exposes metrics about your applications' workflows, steps, and executors from a Prometheus-compatible endpoint, so you can monitor your DBOS applications in Datadog, Grafana, or any other tool that understands the OpenMetrics format.
Architecturally, Conductor looks like this:
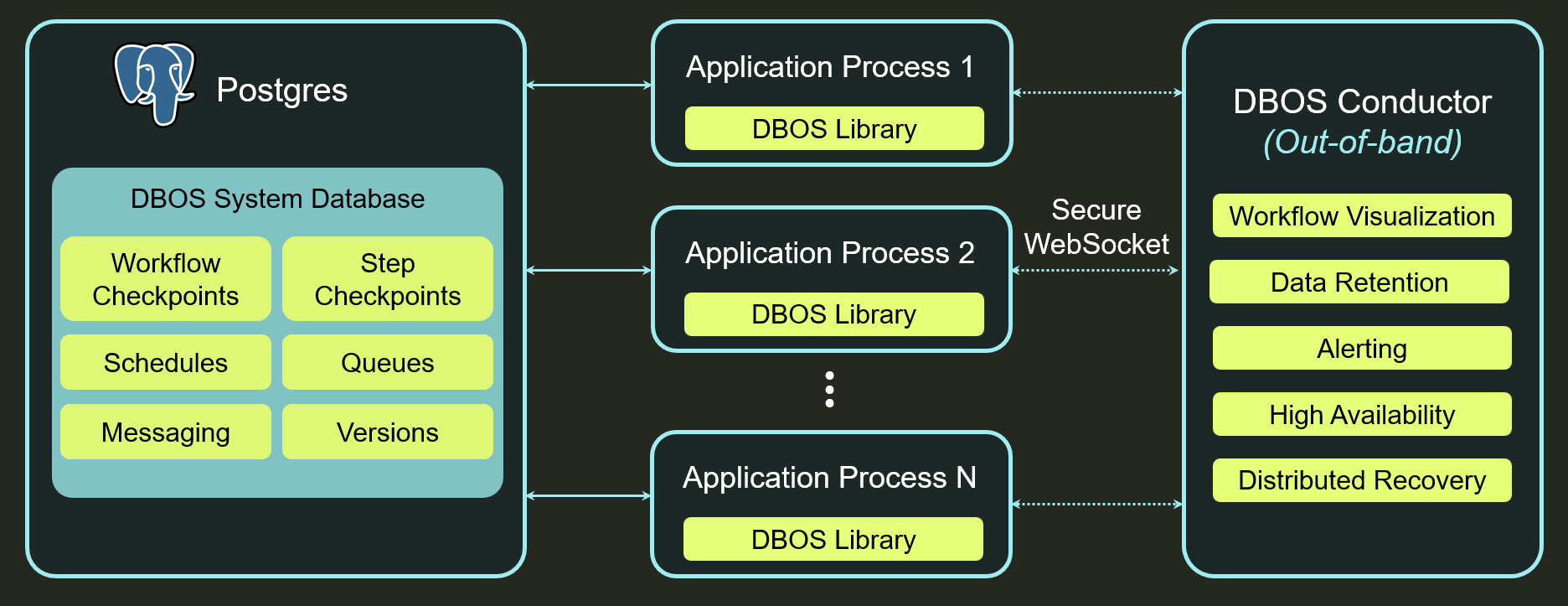
Each of your application servers opens a secure websocket connection to Conductor. All of Conductor's capabilities are powered by these websocket connections. When you open a Conductor dashboard in your browser, your request is sent over websocket to one of your application servers, which serves the request (for example, retrieving a list of recent workflows) and sends the result back through the websocket. If one of your application servers fails, Conductor detects the failure through the closed websocket connection and, after a grace period, directs another server to recover its workflows. This architecture has two useful implications:
- Conductor is secure and privacy-preserving. It does not have access to your database, nor does it need direct access to your application servers. Instead, your servers open outbound websocket connections to it and communicate exclusively through its websocket protocol.
- Conductor is out of band and off your critical path. Conductor is only used for observability and recovery and is never involved in workflow execution (unlike the external orchestrators of other workflow systems). If your application's connection to Conductor is interrupted, it will continue to operate normally, and any failed workflows will automatically be recovered as soon as the connection is restored.
For more information on Conductor, see its docs.